History goes online: Easier access to historical documents with OCR
The important documents take up kilometers of shelves, cabinets and storage space. The archive rooms of the Arolsen Archives are filled with handwritten and typed records that are over 75 years old. Around 26 million of these items can now be found in the online archive.
In May 2020, the Arolsen Archives received the European Heritage Award / Europa Nostra Award 2020 for its online archive, Europe’s highest honor in the field of cultural heritage. “But we’re not stopping at that,” says Director Floriane Azoulay. “The only relevant archives are accessible archives. This is why we are working to make our entire holdings available online. Our goal is to fully index them by 2025.”
It’s a mammoth project, so technical aids and computer-based processes for text recognition and categorization are very important. For the past two and half years or so, the archive team has increasingly used these technologies in addition to manually inputting data.
OCR (optical character recognition) is one of the building blocks for successful text recognition. In the narrowest sense, OCR can identify characters, but it is an error-prone technology, explains Michael Hoffmann, head of the Processes and Quality Management department. In a broader sense, OCR transforms graphical information, such as images, into textual information, meaning metadata. But OCR is just one aspect of the workflow.
For around 50 percent of the collection, OCR and clustering both play a role. 300,000 to 500,000 documents have already been processed and digitized using OCR, and over 8 million documents have been be clustered. Michael Hoffmann explains the role of OCR and other technologies being used for the online archive.

Michael Hoffmann, head of the Processes and Quality Management department
Mr. Hoffmann, what is OCR being used for at the Arolsen Archives?
OCR helps us index uncategorized documents more quickly and economically. We add metadata to them so they are easier to find via the search function.
Is this as simple as it sounds?
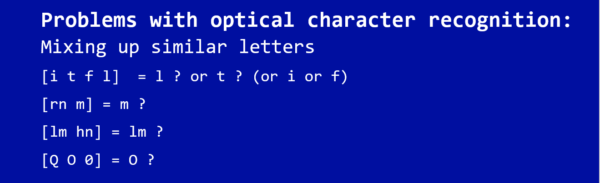
Not entirely. One of the typical problems with optical character recognition is that it can mix up similar letters. For example, a small L might be confused with a big i, rn can become m and hn can become lm. O and 0 are also inevitably problematic.
How are the documents indexed?
First we make the graphical information binary by increasing the contrast and processing the document, so the graphical information is just black and white. Then we eliminate all of the blank spaces and blank characters in what is known as the segmentation. Only then can the actual text recognition process start. The starting material therefore has to be analyzed and prepared first. If a document is misaligned, the lines can get jumbled up. This is why documents need to be carefully prepared. Garbage characters are eliminated and the script is aligned.
Is some of the preparation manual? How time-consuming is this process?
Considering the large number of documents to process, it would be impossible to do this purely manually. The analysis and evaluation of a document bundle, meaning a collection of documents, largely determines which automated processes will be applied to a group of documents. Over time, you start to learn the best way to process a particular document group. Ultimately, the goal is to create the best possible starting point for all following processes. These automated processes often run overnight, so we can continue working on the documents the next day.
What do you use document clustering for?
One special aspect of our collection is that different types of documents were filed together. Specifically, these included various types of index cards, questionnaires and forms relating to concentration camp prisoners. We call this a mixed collection. Clustering sorts the different types of forms into groups. This makes it possible to filter out specific document types, for instance. This is important, because we use pure text recognition to determine how the program will need to read the material to ensure the information elements are correctly identified during the OCR. So clustering is a kind of OCR for layouts and form types.


These examples give you an idea of what is currently possible (and what isn’t).
The image above shows the starting document (a list) and its “raw OCR results” before any post-editing.
In the enlarged detail below, you can see the line within the document, while the text block above shows the OCR results.
The prisoner number “91551” was correctly recognized, although there are rough edges and blurring in the text block; last name was not correctly recognized (D and e not clearly printed, OCR was confused); first name OK; birthdate has mistake in month (a thesaurus could be used afterward to identify the month); birthplace has errors.
Left: different handwritings, adhesive tape partly covers the writing, diagonal writing, stamps, … make the application of OCR difficult.
Do the Arolsen Archives use a special type of OCR?
A combination of many different methods is required for successful text recognition. You could call this combination – which is adapted to the peculiarities of our holdings and materials – the “special type” of OCR used by the Arolsen Archives. But it is more like a collection of the various methods and components that are available. Fundamentally, a variety of steps are necessary for successful text recognition:
- Analysis of the material
- Selection and definition of methods (possibly involving test runs)
- Form recognition (clustering/classification)
- Preparation of images
- OCR
- Data check
- Error correction (automatic or manual)
- Transfer to the database
Optical character recognition is therefore just one component of the whole process.
What are the advantages of optical text recognition?
In the best case, ML text recognition is faster and cheaper than manual indexing. In many use cases, the best practice involves a combination of automated and manual processes, such as clustering with IT tools, which separates a mixed collection into different form types that can then be further processed using the most promising method. In the worst case, the results require extensive post-editing, which makes the whole process inefficient compared to manual indexing. This is why a preliminary analysis of the starting material is just as important as an initial test run. We use the selected technology to turn a few documents into digital documents and then check the error rate. We don’t apply a technology to larger numbers of documents until the initial test run is positive.
What are the limits of the technologies being used?
Handwriting is very difficult and laborious to identify. Many of the documents we index were filled out by hand by different people. It’s not efficient to use OCR on them because the program would have to learn each individual script in advance in order to correctly recognize the characters. This is why we only use technologies on documents that were typed. There is no thesaurus for names, so it is very difficult if not impossible to check them against anything. But we’re currently developing our own reference work.
What procedure is used when?
Machine indexing makes the most sense when we need to check a large number of documents that are very similar, clearly legible and typed. Smaller bundles that require specialist knowledge are manually indexed internally by our experts. For smaller to medium-sized collections with content that is easy to index, we’ve achieved good results with our “Every Name Counts” crowdsourcing project. Via an online platform, volunteers can help us transfer information from the documents to the online database.
What characterizes a good online archive?
Easy access is the key! Both experts and regular users who just want to search for one thing have to be able to find their way around. And without any prior knowledge! It must be self-explanatory and easy to use, and the search options must be designed for both simple and complex searches. The reliability of the search function is especially important. Will the search return everyone with the name I’m looking for? Is the search complete? And we always need to keep the target group in mind. What are they looking for, what do they need, what’s helpful? The archive is designed for finding people – since we used to be a pure tracing service – but today, of course, it is also used for historical research with a focus on specific topics and for archival search topics.