Geschichte geht online: Historische Dokumente leichter zugänglich mit OCR
Die bedeutenden Dokumente füllen kilometerlang Regale, Schränke und Ablagen. Über 75 Jahre alte handschriftliche oder mit Schreibmaschinen getippte Unterlagen reihen sich in den Archivräumen der Arolsen Archives aneinander. Rund 26 Millionen dieser Objekte sind inzwischen im Online-Archiv zu finden.
Im Mai 2020 wurden die Arolsen Archives für das Online-Archiv mit Europas höchster Auszeichnung im Bereich des kulturellen Erbes, den European Heritage Award / Europa Nostra Award 2020, ausgezeichnet. „Aber hier machen wir nicht Halt“, erklärt Direktorin Floriane Azoulay. „Nur zugängliche Archive sind relevante Archive. Darum arbeiten wir daran, den gesamten Bestand online abzubilden. Unser Ziel: Die vollständige Indizierung bis 2025.“
Ein Mammutprojekt. Deshalb werden technische Hilfsmittel und computergesteuerte Verfahren zur Texterkennung und Kategorisierung immer wichtiger. Seit rund zweieinhalb Jahren greift das Team des Archivs neben der manuellen Eingabe von Daten zunehmend auf Technologien zurück.
OCR (optical character recognition), also die optische Zeichenerkennung, stellt einen der Bausteine für eine erfolgreiche Texterkennung dar. OCR kann – im engeren Sinn – Zeichen erkennen, ist aber eine fehlerbehaftete Technologie, erklärt Michael Hoffmann, Referatsleiter für Prozesse und Qualitätsmanagement. Im übergreifenden Sinn wandelt OCR grafische Information, etwa eines Bildes, in textliche Information, also Metadaten, um. OCR beschreibt nur einen Teilaspekt im Workflow.
Bei rund 50 Prozent der Sammlung spielen OCR und Clustering eine Rolle, 300.000 bis 500.000 Dokumente wurden bereits mittels OCR bearbeitet und digitalisiert, über 8 Millionen Dokumente bereits geclustert. Michael Hoffmann erklärt die Rolle von OCR und weiteren Technologien, die für das Online-Archiv genutzt werden.

Herr Hoffmann, wofür wird OCR bei den Arolsen Archives eingesetzt?
Mit OCR können wir schneller und preiswerter noch nicht erfasste Dokumente indizieren. Wir statten sie also mit Metadaten aus und machen sie damit über die Suche einfach auffindbar.
Ist das so einfach, wie es klingt?
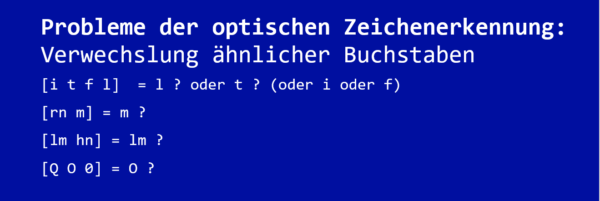
Nicht ganz: Typische Probleme, die bei der optischen Zeichenerkennung auftreten, sind etwa die Verwechslung ähnlicher Buchstaben: So wird ein kleingeschriebenes L zum großgeschriebenen i, rn wird zu m und hn zu lm. Auch das O und die 0 sind für diese Probleme prädestiniert.
Wie läuft die Indizierung der Dokumente ab?
Zunächst werden die grafischen Informationen binarisiert: Wir ziehen den Kontrast hoch und bearbeiten das Dokument. Die grafische Information besteht dann nur noch aus schwarz und weiß – eben binär. Danach eliminieren wir alle Leerstellen und Leerzeichen in der sogenannten Segmentation. Erst im Anschluss geht es um die eigentliche Texterkennung. Das Ausgangsmaterial muss also entsprechend analysiert und vorbereitet werden. Ist es schief ausgerichtet, können Zeilen durcheinandergeraten. Daher müssen Dokumente sorgfältig vorbereitet werden: Störzeichen werden eliminiert, die Schrift wird gerade ausgerichtet.
Ist die Vorbereitung also auch manuell? Wie zeitaufwändig ist so ein Prozess?
Bei der großen Anzahl der zu bearbeitenden Dokumente ist eine rein manuelle Vorbereitung natürlich undenkbar. Die Analyse und Bewertung eines Dokumentenkonvolutes, also einer Sammlung von Dokumenten, entscheidet maßgeblich darüber, welche automatischen Bearbeitungen auf einen Dokumentenbestand angewendet werden. Mit der Zeit stellen sich gewisse Erfahrungswerte ein, wie ein Dokumentenbestand bestmöglich bearbeitet wird. Letztlich ist das Ziel, eine möglichst gute Ausgangsbasis für die Folgeprozesse herzustellen. Solche automatisierten Prozesse laufen oft über Nacht, um am nächsten Tag mit der Weiterbearbeitung fortzufahren.
Wofür nutzen Sie Dokumenten-Clustering?
Eine Besonderheit unserer Sammlungen ist, dass unterschiedliche Arten von Dokumenten zusammengefasst wurden. Ganz konkret sind das zum Beispiel verschiedene Typen von Karteikarten, Fragebögen oder Formularen zu KZ-Häftlingen. Wir nennen das einen Mischbestand. Beim Clustering werden die Formulararten in Gruppen sortiert. Dadurch lassen sich dann zum Beispiel bestimmte Dokumententypen herausfiltern. Das ist wichtig, weil wir bei der reinen Texterkennung vorab festlegen, wie das Programm das Ausgangsmaterial lesen muss, damit beim OCR später die Informationsbausteine korrekt erfasst werden. Clustering ist quasi eine OCR für Layout und Formulararten.


Diese Beispiele geben eine Vorstellung davon, was derzeit machbar ist (und was nicht).
Oben Abgebildet ist das Ausgangsdokument (eine Liste) und deren „OCR-Rohergebnis“ vor einer mögli-chen Nachbearbeitung.
In der Ausschnittsvergrößerung unten sieht man die Zeile innerhalb des Dokumentes und in dem Textblock oben das OCR-Ergebnis.
Die Häftlingsnummer „91551“ wurde korrekt erkannt, obwohl Ausfransungen und Unschärfen im Textblock vorhanden sind; Nachname fehlerhaft erkannt (D und e nicht sauber gedruckt, OCR kommt durcheinander); Vorname OK; Geburtsdatum Fehler im Monat (da wäre nachher ein The-saurus für die Monatsbezeichnungen anwendbar); Geburtsort fehlerhaft.
Links: unterschiedliche Handschriften, Klebestreifen verdecken die Schrift teilweise, quer Geschriebenes, Stempel, … erschweren die Anwendung von OCR.
Wird für die Arolsen Archives eine besondere Form des OCR genutzt?
Für eine erfolgreiche Texterkennung ist eine Vielzahl von unterschiedlichen Methoden in Kombination erforderlich. Diese Kombination – angepasst an die jeweilige Problemstellung des Bestands und Materials – könnte man als „die besondere Form“ für die Arolsen Archives bezeichnen. Dabei handelt es sich eher um eine Methodensammlung unterschiedlicher verfügbarer Bausteine. Grundsätzlich sind für eine erfolgreiche Texterkennung verschiedene Schritte notwendig:
- Analyse des Materials
- Auswahl und Festlegung der Methode (ggf. Testläufe)
- Formularerkennung (Clustering / Klassifizierung)
- Aufbereitung der Images
- OCR
- Datenprüfung
- Fehlerkorrektur (automatisch oder manuell)
- Überführung in die Datenbank
Die optische Zeichenerkennung ist also nur ein Baustein im gesamten Prozess.
Welche Vorteile bietet die optische Texterkennung?
Im besten Fall ist die ML Texterkennung schneller und kostengünstiger gegenüber einer manuellen Erfassung. Es gibt viele Anwendungsfälle, bei der eine Kombination von automatisierten und manuellen Prozessen die best practice darstellt: Etwa beim Clustering mit IT-Mitteln, das einen Mischbestand in unterschiedliche Formulararten zerlegt, welche anschließend mit der erfolgversprechendsten Methode weiterverarbeitet werden. Im worst case muss das Ergebnis aufwendig nachbearbeitet werden. Dadurch wird der komplette Prozess unwirtschaftlich im Vergleich zu einer manuellen Erfassung. Darum ist die vorangehende Analyse des Ausgangsmaterials genauso wichtig wie ein erster Testlauf: Dabei lassen wir einige Dokumente mit der ausgewählten Technik in digitale Dokumente umsetzen und überprüfen im Anschluss die Fehleranfälligkeit. Erst wenn ein erster Testlauf positiv ausfällt, nutzen wir die Technologien für größere Dokumentenmengen.
Wo liegen die Grenzen der verwendeten Technologien?
Handschriften lassen sich nur sehr umständlich und aufwendig erkennen. Viele der Dokumente, die wir indizieren, sind von unterschiedlichen Menschen handschriftlich ausgefüllt worden. Das macht die Nutzung von OCR unwirtschaftlich, da jede einzelne Handschrift zuvor vom Programm gelernt werden müsste, damit sie korrekt erkannt wird. Deswegen nutzen wir die Technologien nur bei Dokumenten, die mit der Schreibmaschine erstellt wurden. Namen haben keinen Thesaurus und können entsprechend nicht oder nur sehr aufwendig abgeglichen werden. Wir arbeiten aber aktuell an einem eigenen Nachschlagewerk.
Welches Verfahren kommt wann zum Einsatz?
Die maschinelle Erfassung ist vor allem dann sinnvoll, wenn eine große Anzahl von Dokumenten überprüft wird, die sich sehr ähnlich sind, die klar lesbar sind und mit der Schreibmaschine ausgefüllt wurden. Kleinere Einheiten, die Fachwissen erfordern, werden intern von unseren Fachleuten manuell indiziert. Für kleinere bis mittelgroße Bestände, deren Inhalte einfach zu erfassen sind, haben wir mit unserem Crowdsourcing-Projekt „Jeder Name zählt“ gute Ergebnisse erzielt: Über eine Online-Plattform können Freiwillige uns dabei helfen, Informationen aus den Dokumenten in die Online-Datenbank zu übertragen.
Was macht ein gutes Online-Archiv aus?
Einfacher Zugang ist der Schlüssel! Sowohl Experten als auch common user, die nur einmal etwas suchen, müssen sich zurechtfinden. Und zwar ohne Vorwissen mitzubringen! Die Handhabung muss selbsterklärend und einfach sein, die Suchmöglichkeiten für einfache und komplexe Suchen ausgelegt. Besonders wichtig ist die Verlässlichkeit der Suche: Werden mir alle Personen mit dem gesuchten Namen angezeigt? Ist die Suche vollständig? Dazu müssen wir immer die Zielgruppe im Blick haben: Wie sucht sie, was braucht sie, was hilft? Das Archiv ist ausgerichtet auf Personensuche – wir waren früher ein reiner Suchdienst – aber heute natürlich auch für historische Forschung mit Fokus auf Sachthemen und für archivarische Suchthemen.