#everynamecounts: New software speeds up digitization

The Arolsen Archives launched #everynamecounts to build a digital memorial to people who were persecuted and murdered by the Nazis. The archive holds over 30 million documents, and the information they contain is being recorded in digital form – large numbers of volunteers are helping us to complete the task. One of them has created a computer program for the project; his name is Thomas Werkmeister, and he’s a software engineer.
Thomas Werkmeister contacted the Arolsen Archives in the spring of 2021 and presented us with an idea. He wanted to work together with our IT team to develop some software that would simplify and accelerate the process of capturing the information contained in the millions of documents in the archive. Due to the pandemic, he couldn’t visit the Arolsen Archives until the project was completed. During his visit to Bad Arolsen, he talked to us about some of the challenges software developers face and told us how it felt to visit the archive for the first time.
How did your collaboration with the Arolsen Archives come about?
It came about by chance really. It all started in January 2021, when I saw the #everynamecounts media installation at the French Embassy in Berlin. I wanted to find out more about it, so I visited the #everynamecounts website and read a blog post written by Michael Hoffmann, the head of the digitization unit at the Arolsen Archives. Michael’s post explains that OCR software, which is supposed to make it easier to digitize documents, has a lot of trouble dealing with lists. OCR stands for Optical Character Recognition. It’s a software solution that can recognize text in scanned documents. OCR software can recognize and process individual letters contained in an image, for example. That was really interesting for me, because I work as a software developer in the field of language and artificial intelligence.
Shortly afterwards, the organizers of the Prototype Fund, a funding program run by the Federal Ministry of Education and Research, asked me if I wanted to apply for project funding – I already knew them from projects I had been involved with in the past. And #everynamecounts came to mind, because I enjoy working on projects that can help organizations and that have a direct practical application. When you develop software, you often don’t realize that nobody actually needs it until it’s finished. That’s not going to happen here, because if the #everynamecounts software turns out to be helpful, it may help other archives in the future too.
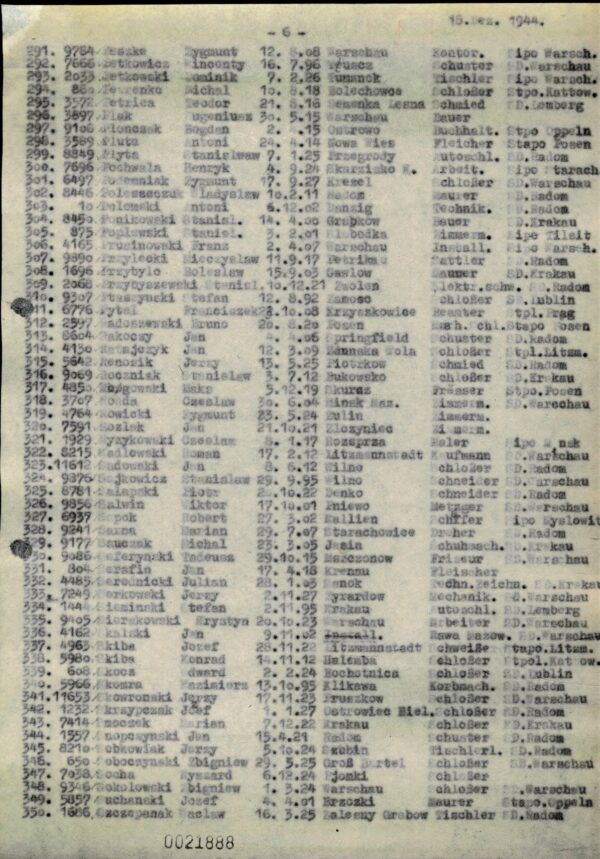
List of Transfers to Buchenwald from December 1944
DocID: 495304
A software solution that saves a lot of time
Can you tell me how your software works exactly?
We used a semi-automated approach that helps users define the table structure for the OCR software. You just have to click to add the frame of the table and the columns. Once this structure is in place, the system knows which information belongs together when it processes the scanned images. Because that’s what was causing problems before. The OCR software would have been able to read the text perfectly, but it wouldn’t have been able to assign the text to the right columns.
How did collaborating with the Arolsen Archives work in practice?
At the beginning, Michael Hoffmann sent me some data sets with lists so I could familiarize myself with the data and the materials. When I saw the first lists from concentration camps, I wasn’t at all sure we’d be able to find a solution, because some of the lists were handwritten, very old, and in poor condition. I discussed the difficulties with Michael, and we decided that the first thing we needed was the table structure, because only when that was in place would the OCR software be able identify which data sets belong together. This approach has enabled us to reduce the time it takes to process a list by two-thirds.

»I was surprised by the phonetic system, the central name index, and the references it contains to the original documents. It’s designed a bit like a search engine, so it’s like an analog form of Google. «
Thomas Werkmeister, Software Engineer
Are there any plans to develop your software solution further?
There are lots of exciting things we could do. We’ve reduced processing times by a third, but even though it now only takes seven minutes to process a list instead of twenty-one, that’s still quite a long time. Staff now spend most of their time proofreading. That’s something we could work on by comparing the data with the existing database. Or we could add an automatic spell checker. Or we could give the program certain values in order to validate the data: if a date of death from the 19th century or a date of birth after 1954 were flagged as probably incorrect, that would bring errors to the attention of the staff.
You’ve been working on the project remotely up until now. How does it feel to be on site for the first time?
It was really good to meet Michael and his team in person for the first time. Up until now, we only knew each other through Zoom. And I found the guided tour fascinating – and the discussions we had in the archive too. The never-ending rows of original documents are a very impressive sight, and they give a good sense of the sheer size of the task at hand. It was also interesting for me to see how the documents are structured. I was surprised by the phonetic system, the central name index, and the references it contains to the original documents. It’s designed a bit like a search engine, so it’s like an analog form of Google. That makes sense, seeing as the main task was to trace victims of Nazi crimes for their relatives. After all, that’s what #everynamecounts is all about.
