#everynamecounts: Neue Software beschleunigt Digitalisierung

Mit #everynamecounts bauen die Arolsen Archives ein digitales Denkmal für die von den Nationalsozialisten verfolgten und ermordeten Menschen. Die über 30 Millionen Dokumente aus dem Archiv werden dazu digital erfasst – auch durch die Mithilfe vieler Freiwilliger. Einer von ihnen, der Softwareentwickler Thomas Werkmeister, hat ein Computerprogramm für das Projekt entwickelt.
Im Frühjahr 2021 meldete sich Thomas Werkmeister mit einem Vorschlag bei den Arolsen Archives: Gemeinsam mit unserem IT-Team wollte er eine Software entwickeln, die die Datenerfassung der Millionen von Dokumenten aus dem Archiv erleichtert und beschleunigt. Bedingt durch die Pandemie, besuchte der Softwareentwickler die Arolsen Archives erst nach Abschluss des Projekts. Bei seinem Besuch in Bad Arolsen erzählte er von den Herausforderungen der Softwareentwicklung und davon, wie es ist, das erste Mal das Archiv zu besuchen.
Wie kam deine Zusammenarbeit mit den Arolsen Archives zustande?
Durch einen Zufall, denn im Januar 2021 habe ich die #everynamecounts-Medieninstallation an der französischen Botschaft in Berlin gesehen. Ich wollte mehr erfahren, habe die Homepage von #everynamecounts besucht und dort einen Blogeintrag von Michael Hoffmann, dem Referatsleiter für Digitalisierung bei den Arolsen Archives, gelesen. In dem Beitrag erklärt Michael, dass die OCR-Software, die das Auslesen der Dokumente erleichtern soll, große Schwierigkeiten mit dem Auslesen von Listen hat. OCR steht für Optical Character Recognition und ist ein Software-Lösung zur automatischen Schrifterkennung. OCR-Software kann zum Beispiel einzelne Buchstaben auf Bildern erkennen und verarbeiten. Das war spannend für mich, denn ich arbeite als Softwareentwickler im Bereich Sprache und künstliche Intelligenz.
Kurze Zeit später fragten die Organisator*innen der Prototypen-Fund-Förderung des Bundesministeriums für Bildung und Forschung., die ich bereits von vergangenen Projekten kannte, ob ich mich mit einem Projekt für die Förderung bewerben wolle. Da fiel mir #everynamecounts wieder ein, denn ich arbeite gerne an Projekten, die Organisationen weiterhelfen können und die auch direkt angewendet werden. Oft wird Software entwickelt und erst dann merkt man: Das braucht niemand. Das ist hier anders, denn wenn die Software #everynamecounts hilft, dann hilft sie in Zukunft vielleicht auch anderen Archiven.
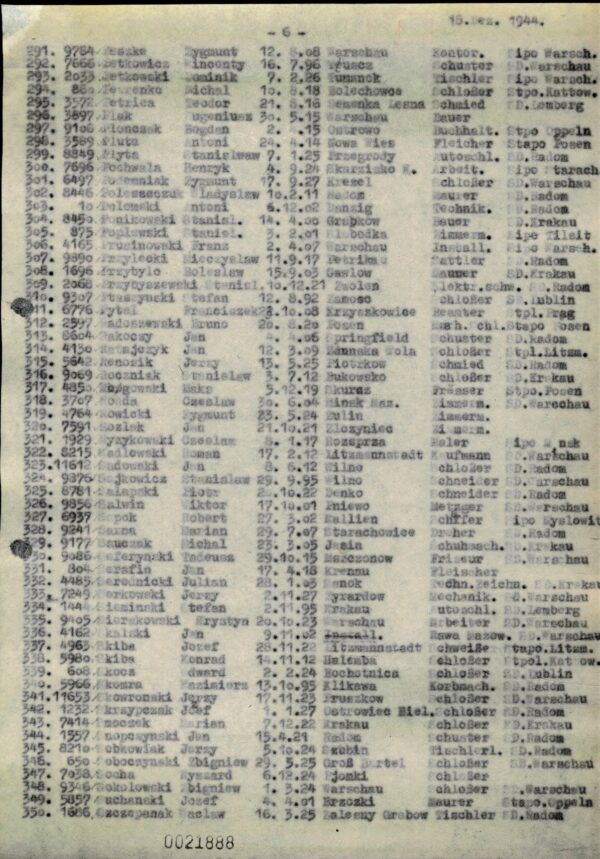
Liste der Zugänge in des KZ Buchenwald aus dem Dezember 1944
DocID:495304
Eine Softwarelösung die viel Zeit spart
Wie genau funktioniert deine Software?
Ein halbautomatisierter Ansatz hilft, die Tabellenstruktur für die OCR-Software vorzugeben. Dafür müssen nur der Rahmen der Tabelle und die Spalten durch Klicks hinzugefügt werden. Wenn diese Struktur steht, weiß das System beim Auslesen, welche Informationen zusammengehören. Denn das war ja das Problem vorher: Die OCR-Software hätte den Text perfekt auslesen, aber nicht in Spalten zuordnen können.
Kannst du erklären, wie die Zusammenarbeit zwischen dir und den Arolsen Archives aussah?
Zunächst hat Michael Hoffmann mir Datensätze mit Listen geschickt, damit ich mich mit den Daten und Materialien vertraut machen konnte. Als ich die ersten Listen aus den Konzentrationslagern gesehen habe, war ich mir gar nicht mehr so sicher, ob wir überhaupt eine Lösung finden können, denn die Listen waren zum Teil handschriftlich, sehr alt und in einem schlechten Zustand. Zusammen mit Michael habe ich überlegt, dass es zunächst die Tabellenstruktur braucht, denn nur so weiß die OCR-Software, welche Datensätze zusammengehören. Damit konnten wir die Zeit, die die Bearbeitung einer Liste dauert, um zwei Drittel reduzieren.

»Das phonetische System, der zentralen Namenskartei, und den Verweisen daraus auf die Originaldokumente, hat mich überrascht. Es ist es konzeptionell aufgebaut wie eine Suchmaschine, also wie die analoge Form von Google.«
Thomas Werkmeister, Softwareentwickler
Gibt es Pläne, deine Software-Lösung noch weiterzuentwickeln?
Da gäbe es viele spannende Möglichkeiten. Wir haben die Zeit der Bearbeitung um ein Drittel reduziert, aber auch wenn es jetzt sieben und nicht mehr 21 Minuten dauert, eine Liste zu bearbeiten, ist das immer noch viel Zeit. Den großen Teil der Zeit verbringen die Mitarbeitenden jetzt mit dem Korrekturlesen. Da könnte man ansetzen und die Daten gegen die bestehende Datenbank abgleichen. Oder eine automatische Rechtschreibprüfung einfügen. Oder man gibt dem Programm bestimmte Werte, um die Daten zu validieren: Wenn ein Sterbedatum aus dem 19. Jahrhundert oder ein Geburtsdatum nach 1954 als vermutlich falsch gekennzeichnet würden, dann könnte das die Aufmerksamkeit der Mitarbeitenden auf Fehler lenken.
Du hast bis jetzt remote an dem Projekt gearbeitet. Wie ist es nun das erste Mal vor Ort zu sein?
Ich habe mich gefreut, Michael und sein Team das erste Mal persönlich zu treffen. Wir kannten uns bis jetzt nur über Zoom. Außerdem waren die Führung und die Diskussionen im Archiv sehr spannend. Die nicht enden wollenden Reihen von Originaldokumenten sind sehr beeindruckend und vermitteln ein Gefühl für die kolossale Aufgabe, die es hier zu bewältigen gilt. Für mich war es außerdem spannend zu sehen, wie die Dokumente strukturiert sind. Das phonetische System, der zentralen Namenskartei, und den Verweisen daraus auf die Originaldokumente, hat mich überrascht. Es ist es konzeptionell aufgebaut wie eine Suchmaschine, also wie die analoge Form von Google. Das macht Sinn, da ja die Hauptaufgabe war, die Menschen, die Opfer von NS-Verbrechen geworden sind, für Angehörige auffindbar zu machen. Das ist schließlich auch die Aufgabe von #everynamecounts.
